Where in the world are you?

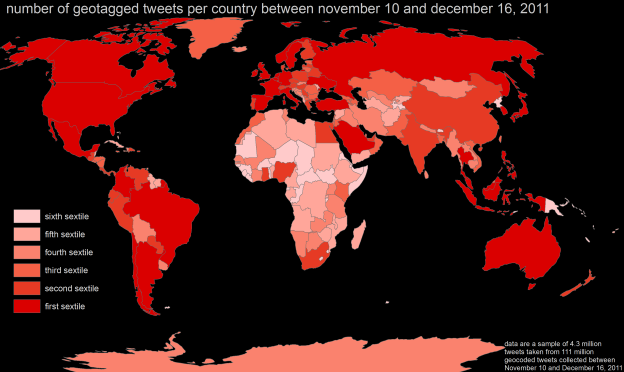
Mark Graham, Scott Hale, and I have written an article about the geolinguistic contours of Twitter mostly for the purpose of improving and exploring methodological choices available to researchers when they are working with Twitter's geographic and language metadata. A full version of the paper is available and the abstract is provided below.
Abstract
The movements of ideas and content between locations and languages are unquestionably crucial concerns to researchers of the information age, and Twitter has emerged as a central, global platform on which hundreds of millions of people share knowledge and information. A variety of research has attempted to harvest locational and linguistic metadata from tweets in order to understand important questions related to the 300 million tweets that flow through the platform each day. However, much of this work is carried out with only limited understandings of how best to work with the spatial and linguistic contexts in which the information was produced.
Furthermore, standard, well-accepted practices have yet to emerge. As such, this paper studies the reliability of key methods used to determine language and location of content in Twitter. It compares three automated language identification packages to Twitter’s user interface language setting and to a human coding of languages in order to identify common sources of disagreement. The paper also demonstrates that in many cases user-entered profile locations differ from the physical locations users are actually tweeting from. As such, these open-ended, user-generated, profile locations cannot be used as useful proxies for the physical locations from which information is published to Twitter.