Some supervision required: LLMs at scale in practice

Recently, I gave a talk at the PIE/Autodesk space to help contextualize some thoughts that have been percolating with regards to the nascent introduction of API-based, widely available LLMs like ChatGPT. In the hype cycle, I've observed some pretty broad claims about what's happening under the hood, what these models are "thinking," how they "reason" about questions, and so forth.
The language we use to describe what an LLM does matters. It allows us to subconsciously extend metaphors about what, as practitioners, we are practicing when we deploy software that is built atop an LLM. Are we simply managing another coworker? Are we just designing a module of code with a fancy regex? Making sense of what an LLM is, and how that informs our implicit estimates of their capabilities and weaknesses, is vital for designing software around LLMs that are likely to be successful long term.
I've been working with "LLMs" since 2017, when I was training fine-tuned transformer models on alt-right texts to try to build a custom classifier that could predict whether or not a particular text was likely to be hate speech - this was inspired by the work that Perspective API was doing at the time, which, during a closed meeting at the time, pre-release, I was totally blown away by the results they were getting. Back in the day, the models were terrible. When the GPT models started rolling out, they were pretty terrible at generating text, which I think humbled my own estimates of what these could do. Here's the sort of thing you could get out of minimaxir's GPT-2-Simple a while back:
Prompt:
"Tell me why bananas are great."
Output:
"Bananas are great because they're a versatile and healthy fruit.
They provide a good source of potassium, which is essential for heart health,
and is essential for heart health, and is essential for heart health,
and is essential for heart health, and is essential for heart health,
and is essential for heart health...."
Largely, the way that these sorts of degenerate behaviors were exorcized from the models was to Just Embiggen Them - to make their parameter space so large, their context so long, that they would just be way less likely to "lose the thread" as it were. Nothing fundamentally changed with the actual implementations - and that's fine! The models got incredibly good by Just Embiggening. The problem, however, was that while, in reality, Embiggening just got them to a point where they were finally acceptably under some sort of threshold of going off the rails, some people assigned a transmutation to the models to having become sentient for some value of the term. As a result, and particularly with folks unfamiliar with the older... less compelling models, they saw the new improved (or, to many, the entirely novel) technology as pure magic, and thus, assigned it commensurate magical capabilities.
As I said before, proper calibration for what these models are allows for a proper calibration for what these models can do in the real world. As a result, I saw some people pitching entirely miscalibrated ideas about what the models would be able to do - obviously, ChatGPT 3.5 has some problems, but surely, the next version or two will be just as huge a step, and we'll be able to just have The Machine do all our jobs! People pitching companies are not following the ball, they are trying to predict where the ball is going, and build the company to meet the ball there in the future. The problem, of course, is that miscalibrated ideas will mean you'll show up at that spot in the future, and the ball could be on the other side of the field.
I decided to put together a talk firming up some of my thinking about where the ball was going, to try to tamp down some of the more grandiose expectations of what Embiggening The Model could possibly achieve. Those are formalized in these slides, and paired with a demonstration technology illustrating the types of things that, to my thinking, are most closely aligned with where I think the ball will end up with the fully mature versions of ChatGPT in the next few years:
At a high level, I argue the following points (roughly slide by slide):
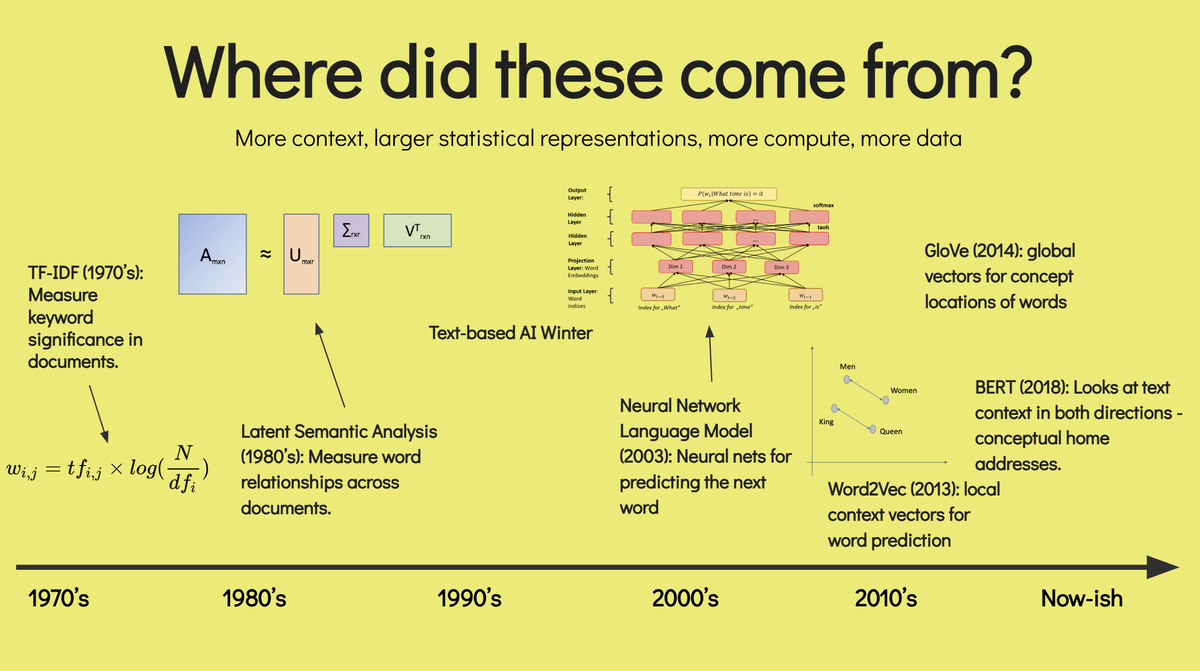
- These models did not come from a vacuum, but are instead the current state of a ≈60 year trajectory in NLP,
- There are some powerful metaphors for what these models are that are relatively accurate, and understanding at a high level what the models actually are is important,
- These models are likely already in the incrementalist phase of increasing accuracy, as we can observe with how accuracy increases as the models get bigger on the only axes we know that improve accuracy,
- The smartest folks in the room are suggesting that the current architectural implementation of these models are unlikely to be sufficient to make some new big leap beyond just Continuing To Embiggen,
- Embiggening another 10x, 100x is likely impossible as we've likely run out of text to train on, likely run out of parameter space to economically afford,
- As a result, we're likely about to hit the wall with increasing levels of autonomy we can provide the models to Just Do Our Work without supervision, and that's likely to be the long term state.
- Some early research suggests that that's ok! Doing semi-supervised work is more than sufficient for some exciting projects - for example, first, ChatGPT 3.5 is as good at basic zero-shot labeling tasks as amazon mechanical turkers, and second, amazon mechanical turkers are arbitraging the models to do their own labeling jobs,
- If the models are being used by these "bellwether" species in the ecosystem, can we use that to anticipate where the ball will go long-term, at least for one category/vertical of product?
- If we assume this to be the direction, then can we build "no-code" ML labelers powered by ChatGPT 3.5 as a potential business? In my example, I provided Siftif.ai, a prototype startup project where people would be able to toss in a few examples of how they'd want a model to label texts, and the algorithm built atop ChatGPT 3.5 would self-improve the original prompt and attempt to find the best way to label texts that mirrored the few-shot examples provided by the user, and in the long limit, replace the model entirely by training a more classical classification model on the already-labeled data generated by the ChatGPT 3.5 corpus. This sort of thing would be much more informed and calibrated for the path dependency of the models, and more sensitive to the strengths and limitations for what they actually can do.
I'll likely turn it off at some point, but in the meantime it's online. For posterity, here's a series of slides for what the Siftif.ai demo looked like:
Siftif.ai Demo