@DudeBro538: I'm not Nate Silver but I play him on Twitter


Background
On December 5th, the following tweet passed through my timeline:
The DudeBro Tournament 2016 pic.twitter.com/z8Ei56dBKX— DudeBroWatch👮🚨 (@DudeBroTourney) December 6, 2016
Embedded JavaScript
To which I replied:
@NateSilver538 please run some bracketology on @DudeBroTourney— Devin 'meat' Gaffney (@DGaff) December 6, 2016
Embedded JavaScript
About 15 minutes later, obviously knowing Nate Silver wouldn't take up the task, I decided I'd go ahead and play the character. And so, I created @DudeBro538:

Confused? I was mostly in the dark at this stage as well. A month earlier, I had learned about the San Francisco punk florist turned Kurdish Rebel volunteer @PissPigGranddad, which served as an entry point to learn about the "Dirtbag Left". The @DudeBroTourney tweet included a NCAA-style bracket that at a glance featured many accounts typically associated with this "Dirtbag Left" group:

What was being setup here was a 63-round Twitter poll NCAA playoff to determine, apparently, the champion of the Dirtbags, I think - I'm still not completely clear what the "point" of this whole thing was, but it's entirely plausible that there wasn't a point. For me, however, the point was incredibly clear: There was going to be 63 Twitter polls, and with all the energy swirling around this joke, someone needed to go all-in and stats the hell out of this thing. Enter @DudeBro538.
Getting Started
In the first round of polls, the statistical analysis was relatively thin: for the first 32 polls, I just ran a binomial test with some python code:
import scipy.stats
pval = scipy.stats.binom_test(int(first), int(first)+int(second), 0.51)
win = 1-pval
other = pval
if win == 1:
print [1, 0]
elif other == 1:
print [0, 1]
else:
print [win, other]
In short, the binomial test just asks a simple question: given a number of trials in which two outcomes are possible, how likely is it that one of the outcomes is ultimately more likely? Analogously, this is like tossing a coin and asking if we can reject a null hypothesis that the coin is fair, that each outcome is equally likely. Once enough data is in (via the number of votes for each contestant in each poll), we can effectively assess that one outcome is, probabilistically speaking, more likely than the other, above some threshold of probability. In this case, once the binomial test was certain that one outcome was more likely than the other, I'd make the guess official:
Some quick takes are clear here - @Pontifex is out, @SusanSarandon is looking great, but @dongoehubaire is burning up the predictions— DudeBro538 (@DudeBro538) December 6, 2016
Embedded JavaScript
Of course, Twitter has yet to roll out any support for Polls in their API. Incredibly frustrating, but surmountable: by using Chrome's network activity inspector, I would manually pull out the JSON request Twitter made to grab the vote counts for each poll. Since the event, the architecture changed a bit, but the general method still works - simply use the inspector to see all the requests your browser is making, find the one that actually requests the Poll data, and then write some code to automate the plucking out of the actual numbers from that poll. For example, with the current iteration of Twitter's polls, here's how one could pull out the data (to get the cURL string, simply right-click the relevant request (it's gonna be /i/cards/tfw/v1/[TWEET_ID])):

require 'nokogiri'
data = `curl 'https://twitter.com/i/cards/tfw/v1/806000156659191808?cardname=poll2choice_text_only&autoplay_disabled=true&earned=true&lang=en&card_height=114&scribe_context=%7B%22client%22%3A%22web%22%2C%22page%22%3A%22permalink%22%2C%22section%22%3A%22permalink%22%2C%22component%22%3A%22tweet%22%7D' -H 'accept-encoding: gzip, deflate, sdch, br' -H 'accept-language: en-US,en;q=0.8' -H 'upgrade-insecure-requests: 1' -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' -H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'referer: https://twitter.com/DudeBroTourney/status/806000156659191808' -H 'authority: twitter.com' -H 'cookie: ct0=36301e19c2a5366002f2242064064990; guest_id=v1%3A148742932194442674; kdt=UrQIvrl51Vmd3JMSDqh0NAKDVeeQl1bK7kZPYLCy; remember_checked_on=1; lang=en; moments_profile_moments_nav_tooltip_self=true; external_referer="GlWr2u5wzZgGipXRLxmupQ==|0"; dnt=1; _ga=GA1.2.1589730768.1487429325; _gat=1; _twitter_sess=BAh7CiIKZmxhc2hJQzonQWN0aW9uQ29udHJvbGxlcjo6Rmxhc2g6OkZsYXNo%250ASGFzaHsABjoKQHVzZWR7ADoPY3JlYXRlZF9hdGwrCOBEslFaAToMY3NyZl9p%250AZCIlOTgwMDdmMjM4YzU2YWY2NzkzMjVmYzQwNDMyMzQ0MWM6B2lkIiUxYjhh%250AMjZhNDAwMmVjMWYyODU2ZDdmNjlmYWEwM2U5OToJdXNlcmwrCQFQlxOUNjAL--51df445066854f2d91eaf9f3a388417ca6390ff3' --compressed`
counts = Hash[Nokogiri.parse(data).search("script")[0].text.split("\n").select{|x| x.include?("count1") || x.include?("count2")}.collect{|x| [x.split(":").first.gsub("\"", "").strip, x.split(":").last.gsub(",", "").to_i]}]
index = 0
candidates = Hash[Nokogiri.parse(data).search(".PollXChoice-pollWrapper label").collect{|x| index +=1 ; [x.inner_text.strip.split("%").last, index]}]
This yields the names of the candidates as well as the number of votes for each candidate, which can then be fed into the Python code from before, which can finally result in an assessment - if there's essentially no chance that the current leader could lose, then I'd go ahead and call it on Twitter. For fun, I also started building out a rough statistical model using the log follower counts for each contestant, the share of votes they received in each round, and the probability of winning each round, all normalized, to generate a "Power Ranking" metric, a joke metric that just bundled up all the potentially relevant data into a single number. To take the joke further, I created the @DudeBro538 polls-plus estimate, which was the same number, but with more value given to that probability of winning a round. The metric was garbage, and ultimately was not very predictive of anything whatsoever, but allowed for very Silveresque tweets like the following:
Clarification: Todd Hitler's down in our PowerRank Polls Plus™, but has slim majority over @Snowden in PowerRank ™ - again, watch next round— DudeBro538 (@DudeBro538) December 7, 2016
Embedded JavaScript
And here was the first lesson of playing a statistician predicting things in real time: always, always leave a door out on either end of things. If it looks probable, don't say it's certain - that way, if your guess goes badly, you can always go back and point to the fact that you had some uncertainty about the outcome, and thus, in a way, you were still right.
Things get out of hand
After the first round, I remembered some code I wrote for a machine learning project a year ago. It's a dirty, dirty trick, and probably doesn't have a huge amount of external validity, but it performs really well for very specific prediction problems. Basically, it takes thousands of permutations of machine learning algorithms to brute-force detect the best possible ensemble for predicting a set of labels. You provide it several dozen algorithms, and it just mixes and matches algorithms randomly, measuring the success for that grouping, and continues doing this until I say stop, at which point I now have a good mixture of algorithms. Ultimately, sklearn's NearestCentroid, RandomForestClassifier, and AdaBoostClassifier proved to be the best set of algorithms to use.
But what was the data I used to feed into the algorithm? The goal of the machine learning code was to predict outcomes of polls that are yet to happen, so each row of the data needed to be a single poll. The label was a bit tricky - ultimately I shaped the dataset like so:
[FIRST CANDIDATE DATA],[SECOND CANDIDATE DATA],[FIRST CANDIDATE WINS]
Where the candidate wins value was 1 if the first candidate in the poll won, and 0 otherwise. But what was the candidate data?
At the time I went with the machine learning route, there were around 1,300 people following the @DudeBroTourney account. I went ahead and downloaded all 1,300 accounts' worth of data, and then for each of the remaining 32 candidates, I downloaded the list of all the accounts that followed both the candidate as well as @DudeBroTourney. This then provided me with a very useful dataset - for each candidate, I knew how many people followed that person on Twitter AND was also paying attention to the tournament. The candidate data was simply a variety of metrics about this group of people - here's the column headers for that dataset:
tweets_count,
age,
listed_count,
friends_count,
favourites_count,
followers_count,
focused_followers_count,
focused_statuses_count,
focused_followers_count,
focused_friends_count,
focused_listed_count,
focused_age,
focused_avg_tweets,
focused_combined_avg_tweets
Where focused denoted the restricted set of people known to follow the candidate as well as the tournament, and the other values were just attributes of the account itself. Getting a good machine prediction wasn't enough, though - we wanted to predict all the future rounds. Once predictions were completed for a particular round, we would need to pair up the survivors to predict that subsequent round, and on and on until there was only a single survivor (the champion). Of course, at round two, there's 32 predictions resulting in 16 survivors in 32 potential combinations, and the next round depends on that particular set of combinations, so we needed to actually feed the tree into some program to keep track of this and set up next stages of the competition accordingly. In other words, we need to literally start simulating the bracket:
input_tree = {"left-top": [["SenSanders", "JeremyCorbyn"],
["emrata", "virgiltexas"],
["CarlBeijer", "DannyDeVito"],
["mtracey", "shailenewoodley"],
["Bashar Al Assad", "nickmullen"],
["See_Em_Play", "carl_diggler"],
["CenkUygur", "Bro_Pair"],
["lhfang", "TheBpDShow"]],
"left-bottom":
[["SusanSarandon", "SenJeffMerkley"],
["CornelWest", "LarryWebsite"],
["mtaibbi", "emmettrensin"],
["cushbomb", "adamjohnsonNYC"],
["RaniaKhalek", "kthalps"],
["sam_kriss", "DougHenwood"],
["rosariodawson", "randygdub"],
["ByYourLogic", "yvessmith"]],
"right-top":
[["ggreenwald", "historyinflicks"],
["robdelany", "roqchams"],
["ckilpatrick", "ebruenig"],
["SenWarren", "pattymo"],
["wikileaks", "Snowden"],
["dongoehubaire", "cascamike"],
["freddiedeboer", "BenjaminNorton"],
["Pontifex", "fart"]],
"right-bottom":
[["MattBruenig", "ninaturner"],
["HAGOODMANAUTHOR", "crushingbort"],
["KillerMike", "willmenaker"],
["PutinRF_Eng", "PissPigGranddad"],
["smoothkobra", "karpmj"],
["AmberALeeFrost", "Trillburne"],
["DrJillStein", "samknight1"],
["davidsirota", "ConnorSouthard"]]}
def chunks(l, n):
"""Yield successive n-sized chunks from l."""
for i in range(0, len(l), n):
yield l[i:i + n]
def generate_next_matchups(tree, winners):
downcased_winners = [e.lower() for e in winners]
new_tree = {"final": [], "left": [], "right": [], "left-top": [], "left-bottom": [], "right-top": [], "right-bottom": []}
if len(winners) == 2:
return {"final": winners}
for i,section in enumerate(tree.keys()):
for j,pair in enumerate(tree[section]):
if pair[0].lower() in downcased_winners:
new_tree[section].append(pair[0])
else:
new_tree[section].append(pair[1])
new_tree[section] = list(chunks(new_tree[section], 2))
if len(new_tree["left-bottom"]) == 1 and len(new_tree["left-bottom"][0]) == 1:
new_tree = {"left": [new_tree["left-top"][0][0], new_tree["left-bottom"][0][0]], "right": [new_tree["right-top"][0][0], new_tree["right-bottom"][0][0]]}
return new_tree
def generate_pairs(tree):
new_pairs = []
if [len(e) for e in tree.values()] == [2,2]:
return tree.values()
elif [len(e) for e in tree.values()] == [2]:
return [tree.values()][0]
else:
for pair_set in tree.values():
for pair in pair_set:
new_pairs.append(pair)
return new_pairs
comp_map = {}
for comp1 in comps:
comp_map[comp1] = {'wins_against': [], 'loses_against': []}
for comp2 in comps:
if comp1 != comp2:
row = []
[row.append(el) for el in transformed_dataset[comp1.lower()]]
[row.append(el) for el in transformed_dataset[comp2.lower()]]
result = (np.transpose([m.predict([row]) for m in trained_model]).sum(1,)/float(len(trained_model))).tolist()[0]
results = []
for i in range(50):
rand = random.random()
if result >= 0.5:
if rand < model_accuracy:
results.append(1)
else:
results.append(0)
else:
if rand < model_accuracy:
results.append(0)
else:
results.append(1)
if np.mean(results) >= 0.5:
comp_map[comp1]["wins_against"].append(comp2)
else:
comp_map[comp1]["loses_against"].append(comp2)
def run_tournament(input_tree, setup_pairs, cur_round = 1, comps = comps):
tree = input_tree
pairs = generate_pairs(tree)
winners = []
winner_sets = []
furthest_rounds = {}
for comp in comps:
furthest_rounds[comp] = cur_round
while len(winners) != 1:
fitting_dataset = []
for pair in pairs:
row = []
[row.append(el) for el in transformed_dataset[pair[0].lower()]]
[row.append(el) for el in transformed_dataset[pair[1].lower()]]
fitting_dataset.append(row)
winners = []
results = (np.transpose([m.predict(fitting_dataset) for m in trained_model]).sum(1,)/float(len(trained_model))).tolist()
for i,guess in enumerate(results):
result = random.random()
if guess >= 0.5:
if result < model_accuracy:
winners.append(pairs[i][1])
furthest_rounds[pairs[i][0]] = cur_round
else:
winners.append(pairs[i][0])
furthest_rounds[pairs[i][1]] = cur_round
else:
if result < model_accuracy:
winners.append(pairs[i][0])
furthest_rounds[pairs[i][1]] = cur_round
else:
winners.append(pairs[i][1])
furthest_rounds[pairs[i][0]] = cur_round
winner_sets.append(winners)
if len(winners) == 1:
furthest_rounds[winners[0]] = cur_round+1
return [winners, winner_sets, furthest_rounds]
tree = generate_next_matchups(tree, winners)
pairs = generate_pairs(tree)
cur_round += 1
At this point, this allowed for some interesting possibilities - I now had code that could predict outcomes well, and also feed those results into the next rounds to determine the ultimate consequences of those matchups. I then added a bit of random noise - even though the machine learning was deterministic in its judgements (once the model was trained), 20% of the time the winner would be the underdog according to the machine learning judgement. Then, to go full Silver, I ran the competition thousands of times, and simply counted the number of times each account ended up being the champion. In a hand-waving sense, this provided the average expected probability that each account would win the tournament:
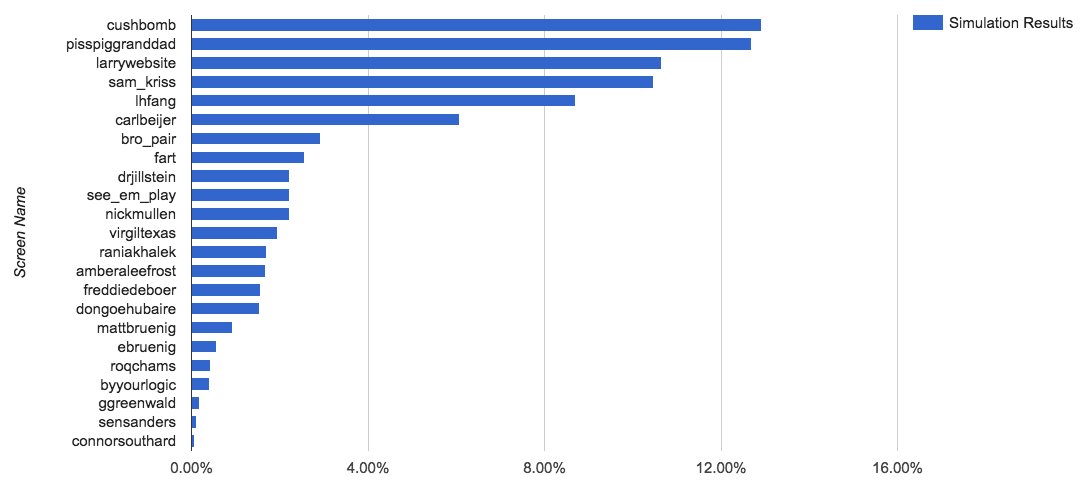
The x-axis here is simply the percent of tournaments, in several thousand iterations, that a particular account won. At this time, there were still 32 contestants in the tournament, and the machine learner had accurately found the accounts that were popular in this community on Twitter, and was predicting likely wins for them after the first round.
Now that I had the ability to run the bracket as a series of simulations, that unleashed the ability to start making ridiculous prognostications, both about the real predictions at hand as well as impossible-to-verify-but-fun-to-read counterfactuals. For example, we could randomly pair up candidates regardless of their original positions in the bracket:
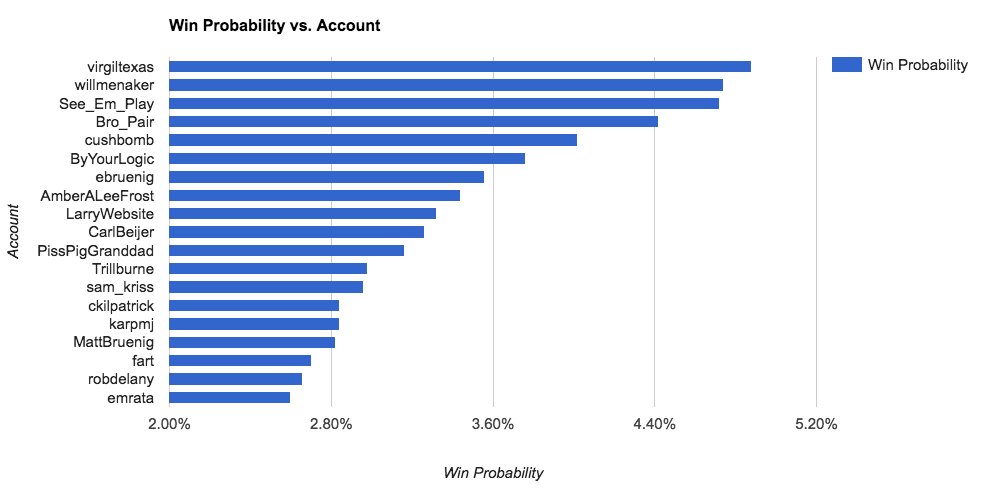
We could randomly set the bracket again and measure the number of rounds, on average, an account would get further into the bracket versus the actual bracket at hand:
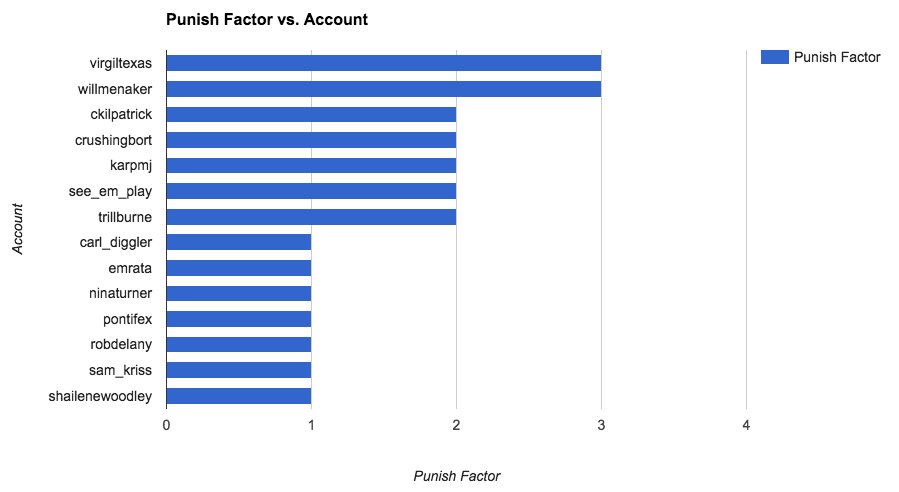
Or the opposite question of who was most advantaged by the bracket's seeding:
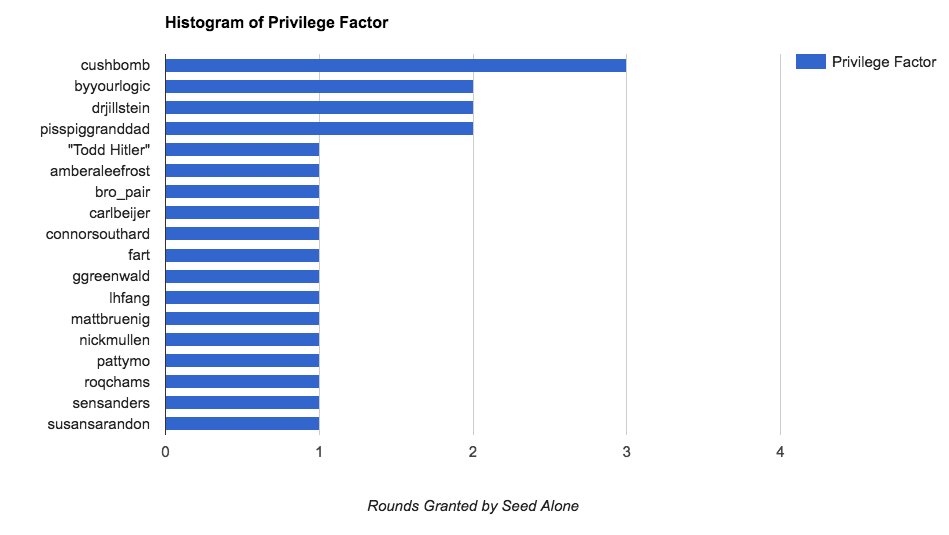
We could also play out counterfactuals in real time when the polls were still open:
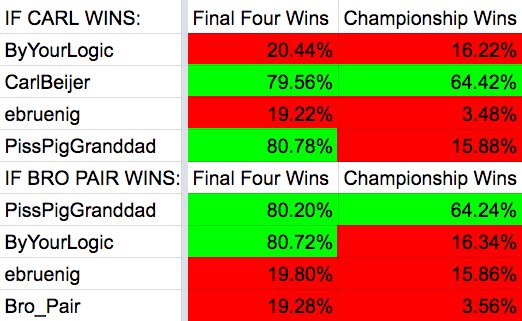
I could also wrap these stats in thin narratives that left plenty of room to still be right regardless of outcome:
Here's the reason the model's likely saying this: @ebruenig is strong and breaks tradition, but not enough - if @PissPigGranddad.. 1/— DudeBro538 (@DudeBro538) December 10, 2016
Embedded JavaScript
In all the tweets, I could talk about "the model" as some abstract, anthropomorphic figure with it's own "intent" and behavior independent of mine - if something weird happened, it wasn't my fault, it was the model's uncertainty. Under all of the hedging, though, was a bona fide model that was absurdly complicated.
Wrapping up
Ultimately, the machine learning code performed almost perfectly:
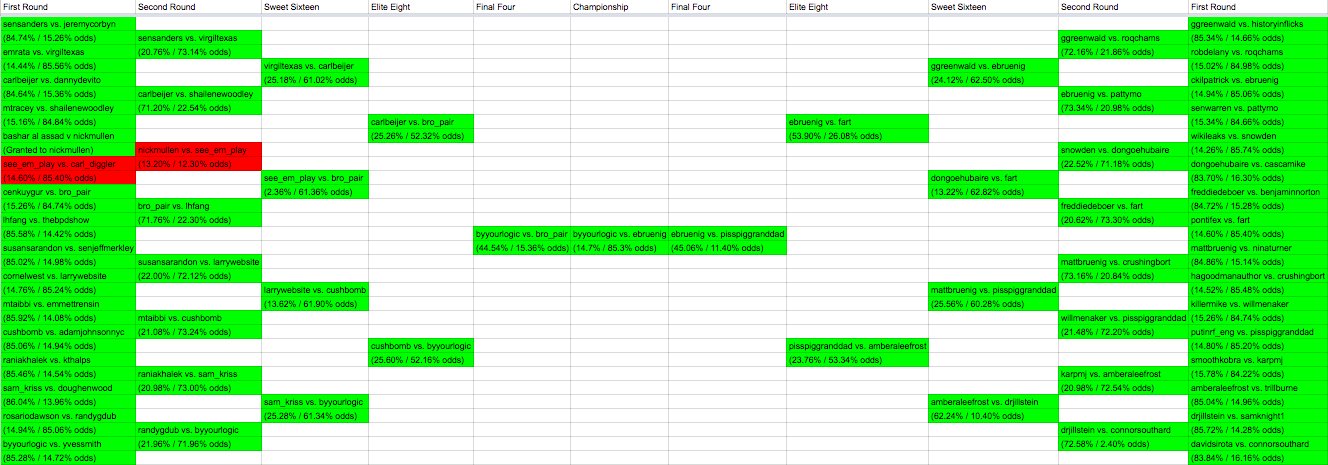
In all but two tournaments, the machine learner was able to correctly predict the outcome. A huge spreadsheet live-tracked all of the work, and ultimately, of the 63 tournaments, I failed to correctly call only 3 of them. With a mixture of binomial tests, machine learner modeling, and dirty rhetorical hedging, @DudeBro538 was able to capture the look and feel of a real prediction process within the think piece-industrial complex of Twitter where everyone wants the smartest "take".
Ultimately, I learned a few lessons, some statistical and some rhetorical. Statistically speaking, while the model I ultimately developed may not be generalizable to anything useful whatsoever, it was internally valid and correctly judged the competition - in two cases now, this machine learning approach can get the job done, though it may be terrible at most other things, and is certainly far from scientifically valid as far as I can tell. Rhetorically, that didn't matter, since it was internally working well, and in the cases where it may not work well, hold off on making a "call" for a competition until victory is all but certain owing to time left, so that retrospectively @DudeBro538 looks like an authority in prediction, and in the cases where a call may be wrong, as well as in long term predictions, use hedging rhetoric that puts errors solidly on the model and "probability" in an ambiguous sense such that you can retrospectively post the tweet equivalent of ¯\_(ツ)_/¯.
Appendix
Here's the full Python code:
import collections
import operator
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.mlab as mlab
import os
import random
import itertools
from sklearn.neighbors.nearest_centroid import NearestCentroid
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import csv
from sklearn.ensemble import AdaBoostClassifier
model_accuracy = 0.85
def read_csv(filename):
dataset = []
i = 0
with open(filename, 'rb') as f:
reader = csv.reader(f)
for row in reader:
if i != 0:
dataset.append(row)
i += 1
return dataset
model = (AdaBoostClassifier(algorithm='SAMME.R', base_estimator=None,
learning_rate=1.0, n_estimators=100, random_state=None),)
dataset = "ml_dataset.csv"
pairs_file = "pairs.csv"
setup_pairs = read_csv(pairs_file)
transformed_dataset = {}
for row in read_csv(dataset):
transformed_dataset[row[0].lower()] = [float(el) for el in row[2:]]
transformed_dataset["bashar al assad"] = np.average(np.transpose(transformed_dataset.values()), 1)
fitting_dataset = []
fitting_labels = []
max_round = int(sorted([el[-1] for el in setup_pairs])[-1])
for pair in setup_pairs:
fitting_labels.append(int(pair[2]))
cur_round = int(pair[3])
row = []
[row.append(el) for el in transformed_dataset[pair[0].lower()]]
if cur_round == 1:
row[-max_round] = 0
if cur_round <= 2:
row[-(max_round-1)] = 0
if cur_round <= 3:
row[-(max_round-2)] = 0
if cur_round <= 4:
row[-(max_round-3)] = 0
if cur_round <= 5:
row[-(max_round-4)] = 0
if cur_round <= 6:
row[-(max_round-5)] = 0
[row.append(el) for el in transformed_dataset[pair[1].lower()]]
if cur_round <= 1:
row[-max_round] = 0
if cur_round <= 2:
row[-(max_round-1)] = 0
if cur_round <= 3:
row[-(max_round-2)] = 0
if cur_round <= 4:
row[-(max_round-3)] = 0
if cur_round <= 5:
row[-(max_round-4)] = 0
if cur_round <= 6:
row[-(max_round-5)] = 0
fitting_dataset.append(row)
trained_model = [m.fit(fitting_dataset, fitting_labels) for m in model]
input_tree = {"left-top": [["SenSanders", "JeremyCorbyn"],
["emrata", "virgiltexas"],
["CarlBeijer", "DannyDeVito"],
["mtracey", "shailenewoodley"],
["Bashar Al Assad", "nickmullen"],
["See_Em_Play", "carl_diggler"],
["CenkUygur", "Bro_Pair"],
["lhfang", "TheBpDShow"]],
"left-bottom":
[["SusanSarandon", "SenJeffMerkley"],
["CornelWest", "LarryWebsite"],
["mtaibbi", "emmettrensin"],
["cushbomb", "adamjohnsonNYC"],
["RaniaKhalek", "kthalps"],
["sam_kriss", "DougHenwood"],
["rosariodawson", "randygdub"],
["ByYourLogic", "yvessmith"]],
"right-top":
[["ggreenwald", "historyinflicks"],
["robdelany", "roqchams"],
["ckilpatrick", "ebruenig"],
["SenWarren", "pattymo"],
["wikileaks", "Snowden"],
["dongoehubaire", "cascamike"],
["freddiedeboer", "BenjaminNorton"],
["Pontifex", "fart"]],
"right-bottom":
[["MattBruenig", "ninaturner"],
["HAGOODMANAUTHOR", "crushingbort"],
["KillerMike", "willmenaker"],
["PutinRF_Eng", "PissPigGranddad"],
["smoothkobra", "karpmj"],
["AmberALeeFrost", "Trillburne"],
["DrJillStein", "samknight1"],
["davidsirota", "ConnorSouthard"]]}
def chunks(l, n):
"""Yield successive n-sized chunks from l."""
for i in range(0, len(l), n):
yield l[i:i + n]
def generate_next_matchups(tree, winners):
downcased_winners = [e.lower() for e in winners]
new_tree = {"final": [], "left": [], "right": [], "left-top": [], "left-bottom": [], "right-top": [], "right-bottom": []}
if len(winners) == 2:
return {"final": winners}
for i,section in enumerate(tree.keys()):
for j,pair in enumerate(tree[section]):
if pair[0].lower() in downcased_winners:
new_tree[section].append(pair[0])
else:
new_tree[section].append(pair[1])
new_tree[section] = list(chunks(new_tree[section], 2))
if len(new_tree["left-bottom"]) == 1 and len(new_tree["left-bottom"][0]) == 1:
new_tree = {"left": [new_tree["left-top"][0][0], new_tree["left-bottom"][0][0]], "right": [new_tree["right-top"][0][0], new_tree["right-bottom"][0][0]]}
return new_tree
def generate_pairs(tree):
new_pairs = []
if [len(e) for e in tree.values()] == [2,2]:
return tree.values()
elif [len(e) for e in tree.values()] == [2]:
return [tree.values()][0]
else:
for pair_set in tree.values():
for pair in pair_set:
new_pairs.append(pair)
return new_pairs
comp_map = {}
for comp1 in comps:
comp_map[comp1] = {'wins_against': [], 'loses_against': []}
for comp2 in comps:
if comp1 != comp2:
row = []
[row.append(el) for el in transformed_dataset[comp1.lower()]]
[row.append(el) for el in transformed_dataset[comp2.lower()]]
result = (np.transpose([m.predict([row]) for m in trained_model]).sum(1,)/float(len(trained_model))).tolist()[0]
results = []
for i in range(50):
rand = random.random()
if result >= 0.5:
if rand < model_accuracy:
results.append(1)
else:
results.append(0)
else:
if rand < model_accuracy:
results.append(0)
else:
results.append(1)
if np.mean(results) >= 0.5:
comp_map[comp1]["wins_against"].append(comp2)
else:
comp_map[comp1]["loses_against"].append(comp2)
def run_tournament(input_tree, setup_pairs, cur_round = 1, comps = comps):
tree = input_tree
pairs = generate_pairs(tree)
winners = []
winner_sets = []
furthest_rounds = {}
for comp in comps:
furthest_rounds[comp] = cur_round
while len(winners) != 1:
fitting_dataset = []
for pair in pairs:
row = []
[row.append(el) for el in transformed_dataset[pair[0].lower()]]
[row.append(el) for el in transformed_dataset[pair[1].lower()]]
fitting_dataset.append(row)
winners = []
results = (np.transpose([m.predict(fitting_dataset) for m in trained_model]).sum(1,)/float(len(trained_model))).tolist()
for i,guess in enumerate(results):
result = random.random()
if guess >= 0.5:
if result < model_accuracy:
winners.append(pairs[i][1])
furthest_rounds[pairs[i][0]] = cur_round
else:
winners.append(pairs[i][0])
furthest_rounds[pairs[i][1]] = cur_round
else:
if result < model_accuracy:
winners.append(pairs[i][0])
furthest_rounds[pairs[i][1]] = cur_round
else:
winners.append(pairs[i][1])
furthest_rounds[pairs[i][0]] = cur_round
winner_sets.append(winners)
if len(winners) == 1:
furthest_rounds[winners[0]] = cur_round+1
return [winners, winner_sets, furthest_rounds]
tree = generate_next_matchups(tree, winners)
pairs = generate_pairs(tree)
cur_round += 1
setup_pairs = generate_pairs(tree)
tourney_results = []
tourney_results_per_round = []
furthest_round_set = []
for i in range(5000):
winner, winner_set, furthest_rounds = run_tournament(input_tree, setup_pairs)
tourney_results.append(winner[0])
tourney_results_per_round.append(winner_set)
furthest_round_set.append(furthest_rounds)
collections.Counter(tourney_results)
ml_dataset.csv:
screen_name,won,tweets_count,age,listed_count,friends_count,favourites_count,followers_count,focused_followers_count,focused_statuses_count,focused_followers_count,focused_friends_count,focused_listed_count,focused_age,focused_avg_tweets,focused_combined_avg_tweets,vote_count_1,vote_count_2,vote_count_3,vote_count_4,vote_count_5
adamjohnsonNYC,0,66144,1576.776126,927,990,22420,35562,442,10798.94808,850.5233645,807.6137072,28.894081,1676.392012,1.08E-09,6.441779723,983,0,0,0,0
AmberALeeFrost,1,24014,652.9099341,193,493,48367,12541,448,6227.486425,353.5113122,551.8710407,12.86199095,1457.562587,7.40E-10,4.272534488,2260,2800,2666,1793,0
BenjaminNorton,0,49348,1530.686034,912,497,28500,28479,1176,13635.89732,1476.511161,1023.584821,46.02008929,1603.745904,1.43E-09,8.502529785,632,0,0,0,0
Bro_Pair,1,152017,2704.616809,893,1444,94520,42053,483,9594.056973,1067.033163,738.9829932,26.04421769,1697.344168,9.24E-10,5.65239338,3053,2061,2308,2318,911
ByYourLogic,1,33294,336.2150267,354,1012,69142,23768,1173,6727.178054,316.184265,592.4741201,13.80745342,1415.547594,8.83E-10,4.752350312,3169,3309,0,2768,2386
carl_diggler,0.00,4169,421.0807443,176,311,1140,13766,523,9163.900919,775.7701736,739.7773238,23.84167518,1674.8316,8.65E-10,5.471535708,1926,0,0,0,0
CarlBeijer,1,399,1500.016589,300,1051,30943,13943,293,10102.73743,1005.663257,738.170503,25.72293265,1655.91378,1.01E-09,6.101004493,2663,2692,1878,2283,0
cascamike,0,7860,1967.790443,251,740,6306,12271,72,12373.48042,1466.060052,1033.966057,47.49347258,1654.915182,1.36E-09,7.476806392,1056,0,0,0,0
cenkuygur,0,18931,1829.129344,3672,476,2233,261675,525,9235.48503,934.491018,1058.712575,35.9491018,1630.155404,1.19E-09,5.665401595,816,0,0,0,0
ckilpatrick,1,39726,3032.202747,320,869,19048,2998,37,9031.916667,1014.496212,739.4185606,25.45265152,1622.85458,9.15E-10,5.56545039,1735,0,0,0,0
ConnorSouthard,0,30986,1420.666612,80,672,78721,2998,90,11676.04015,1661.087954,813.789675,33.00573614,1540.162417,1.15E-09,7.581044714,696,1254,0,0,0
CornelWest,0,2812,2778.098939,11295,165,405,748869,350,8942.620219,905.2540984,846.1748634,30.86612022,1514.889003,1.04E-09,5.90315211,1356,0,0,0,0
crushingbort,1,7670,2281.79071,996,894,65738,45559,1065,10194.97267,1127.016023,744.7049953,25.76154571,1689.45194,9.35E-10,6.03448516,2360,1154,0,0,0
cushbomb,1,85544,2841.706416,354,898,240055,18220,937,9487.520883,953.7360126,701.4507486,23.62096139,1657.853543,9.07E-10,5.722773833,2320,2685,2645,1224,0
DannyDeVito,0,6924,2650.07564,23350,20,86,3951680,944,6014.590476,540.0380952,797.9333333,14.60952381,1492.941684,9.31E-10,4.028684133,1276,0,0,0,0
davidsirota,1,56837,3122.357017,2785,2693,3141,2429,34,11488.23944,1016.919517,982.3299799,37.63380282,1663.508621,1.30E-09,6.906029393,460,0,0,0,0
dongoehubaire,0,16760,229.1872374,60,294,30074,13991,23,9556.660333,1390.627078,792.4418052,23.34679335,1536.566646,1.07E-09,6.219489632,2241,2335,2163,0,0
DougHenwood,1,36033,2891.810096,609,1919,4107,284411,131,11886.83429,1888.674286,883.6952381,42.91238095,1720.940959,1.12E-09,6.907171461,940,0,0,0,0
DrJillStein,1,11155,2498.693244,3663,3545,14989,24017,13,8692.73494,689.746988,850.746988,27.3253012,1359.229831,1.45E-09,6.395338552,1492,1633,883,0,0
ebruenig,1,58,1286.602191,687,1911,88181,24017,0,9940.284492,1186.951872,803.6417112,28.03529412,1695.211871,9.36E-10,5.863741667,2103,2500,1979,2636,1732
emmettrensin,0,22970,1408.584633,341,995,4957,12358,87,10869.39477,880.9532325,820.9050894,28.85006878,1623.923853,1.06E-09,6.69329091,1331,0,0,0,0
emrata,0,1671,1693.931034,2354,325,840,910602,14,8175.069444,391.8472222,1011.444444,16.79166667,1549.170512,9.30E-10,5.277062391,353,0,0,0,0
fart,1,68755,3186.9213,2786,1245,45061,116811,51,7302.250526,1085.035789,679.2042105,17.73684211,1477.248552,8.08E-10,4.943142787,3217,2599,2418,1732,0
freddiedeboer,1,24626,1063.806346,450,102,47183,21569,31,8897.583244,1121.025779,760.141783,26.96455424,1642.252225,9.20E-10,5.417915167,2421,2303,0,0,0
ggreenwald,1,87080,3019.76402,18248,990,80,781065,92,7137.308378,1228.632799,630.7308378,22.13012478,1360.380977,1.04E-09,5.246551144,2452,1974,1295,0,0
HAGOODMANAUTHOR,0,34608,930.9477582,397,3844,19179,20090,486,12591.72222,1834.311111,1420.733333,72.57777778,1526.643686,2.07E-09,8.24797714,355,0,0,0,0
historyinflicks,0,58852,903.4035337,136,724,90411,7450,1031,12052.21199,1275.406433,813.4049708,27.05116959,1598.716227,1.25E-09,7.538681212,1313,0,0,0,0
jeremycorbyn,0,6604,2476.241902,3792,2291,103,679354,955,5539.509615,288.1442308,546.6057692,13.34615385,1316.456254,7.38E-10,4.207894942,1238,0,0,0,0
karpmj,1,8597,2185.929749,176,1031,9869,8601,979,9331.001218,1110.695493,775.7965895,26.46163216,1622.327737,9.66E-10,5.751612945,1831,652,0,0,0
KillerMike,0,111671,2848.825536,2201,1834,4143,246012,383,10656.93915,1212.965608,968.7380952,38.22751323,1625.037129,1.18E-09,6.55796656,1342,0,0,0,0
kthalps,0,32209,3036.716462,692,3624,3198,16048,78,10881.43189,1392.205882,875.2585139,32.9876161,1646.873616,1.16E-09,6.607326617,1022,0,0,0,0
LarryWebsite,1,38816,792.8521101,215,213,32295,12874,1056,9589.055399,1014.089202,751.77277,24.27230047,1644.494366,9.65E-10,5.831005315,1980,2231,1412,0,0
lhfang,1,6927,3415.633395,1571,1870,9755,59754,1061,9799.385165,1152.632708,755.0500447,29.4512958,1631.035561,1.01E-09,6.008075722,2750,1797,0,0,0
MattBruenig,1,263,1986.400478,781,658,11031,272157,1269,9819.011905,910.0238095,737.1292517,27.90136054,1670.082886,9.50E-10,5.879356035,2323,2126,1555,0,0
mtaibbi,1,8264,2772.035976,8125,2012,1282,282629,81,8479.359404,682.7374302,740.7802607,21.8603352,1505.469523,1.04E-09,5.632368686,1745,923,0,0,0
mtracey,1,69296,2826.709656,1287,1342,5187,28976,421,9295.875635,1300.428934,951.5964467,42.84771574,1576.474941,1.26E-09,5.896621233,1523,0,0,0,0
nickmullen,0,32928,2790.183001,396,947,25285,96029,935,8832.712276,1202.547315,720.0102302,23.10613811,1658.658381,8.05E-10,5.325214861,2326,1862,0,0,0
ninaturner,1,24150,2281.22123,1471,3950,43198,39299,727,11415.3125,1687.300481,969.7644231,41.12259615,1610.201938,1.24E-09,7.089367007,638,0,0,0,0
pattymo,0,98187,3544.160316,542,865,255036,39299,60,10256.42788,746.4711538,782.4951923,21.46634615,1672.262308,9.62E-10,6.133264998,2288,1414,0,0,0
PissPigGranddad,1,10348,1810.54711,81,645,23257,13185,222,9556.701271,1117.648305,711.621822,24.80720339,1623.761973,9.64E-10,5.885530896,2595,2272,2302,2077,1651
Pontifex,0,1035,1749.413615,25103,8,0,10079572,931,2606.243243,222.0540541,780.3243243,6.27027027,1250.172793,5.92E-10,2.084706416,1857,0,0,0,0
PutinRF_Eng,0,1381,1491.286173,2713,16,41,499259,227,10516.47826,593,988.3913043,34.2173913,1165.424664,2.23E-09,9.023730648,265,0,0,0,0
randygdub,1,49607,2750.97189,205,802,49364,13333,684,10652.35874,1099.091928,724.0347534,22.86098655,1673.190383,9.65E-10,6.366495317,1822,995,0,0,0
RaniaKhalek,1,63320,2775.022492,2834,1811,22022,101604,58,4735.778626,782.3435115,517.1755725,17.09160305,1280.538282,8.79E-10,3.698271805,1605,1521,0,0,0
RobDelany,0,6,1799.693268,37,1,1,3643,821,7527.846154,306.6153846,603.3076923,11.23076923,1543.974753,1.37E-09,4.87562775,1438,0,0,0,0
roqchams,1,12698,2705.785524,1276,291,9946,25248,646,10590.42137,1288.737095,792.8727491,30.59303721,1674.023284,1.01E-09,6.326328588,2174,1934,0,0,0
rosariodawson,0,18535,2609.134541,6598,968,35715,597157,1119,12001.3625,1320.8625,1043.520833,44.42083333,1677.675668,1.37E-09,7.153565333,1232,0,0,0,0
sam_kriss,1,23574,1658.882203,264,593,10459,16893,360,8724.471065,1116.577546,762.7916667,24.20023148,1615.632685,8.75E-10,5.400033766,2259,1825,901,0,0
samknight1,0,112764,2771.219541,339,3680,66284,9652,70,10627.96741,1021.93279,859.8574338,31.44195519,1546.137401,1.13E-09,6.873882878,1259,0,0,0,0
See_Em_Play,1,38514,1603.987075,121,765,59435,9207,782,0,0,0,0,0,0,0,2086,1989,1527,0,0
SenJeffMerkley,0,3686,2802.329911,2531,526,19,52813,416,11056.2069,559.0344828,1310.149425,31.5862069,1674.886164,1.80E-09,6.601169161,562,0,0,0,0
SenSanders,1,15686,2801.354957,17514,1973,24,3252923,832,3175.384615,199,395.9487179,10.8974359,1275.896582,1.28E-09,2.488747646,2918,2129,0,0,0
SenWarren,1,1379,1473.263383,8296,254,5,1196079,892,7065.934211,294.3421053,655.2236842,12.46052632,1431.648535,1.16E-09,4.935522957,1631,0,0,0,0
shailenewoodley,0,2956,1826.173638,2684,725,633,1196079,830,5041.435897,207.6666667,758.7051282,9.730769231,1527.670918,8.77E-10,3.300079773,1938,955,0,0,0
smoothkobra,0,181244,2833.705062,398,20186,78208,28658,237,16534.5,790.0333333,1503.7,27,1550.048686,1.73E-09,10.6670843,793,0,0,0,0
Snowden,1,1562,727.0064272,17315,1,0,2637491,864,5432.050633,1077.075949,542.1265823,24.83544304,1104.4982,7.78E-10,4.918116327,2528,1618,0,0,0
SusanSarandon,1,5764,1626.147643,3207,333,3595,456035,491,12314.09607,1184.227074,1074.816594,44.26637555,1699.066455,1.34E-09,7.247565878,2543,1439,0,0,0
TheBpDShow,0,31128,709.3160337,1467,1210,53415,25035,75,10867.22222,935.5041152,824.781893,31.72839506,1560.789241,1.13E-09,6.962645509,795,0,0,0,0
Trillburne,0,60976,1994.699286,257,1206,116903,14070,30,9002.14258,940.0727449,727.8836081,21.31522793,1624.449044,9.24E-10,5.54165894,848,0,0,0,0
virgiltexas,1,44157,3027.158638,595,889,83652,27379,1217,8994.126541,1046.098603,693.6614626,24.46589975,1660.584703,8.52E-10,5.416240747,2363,2337,1831,0,0
wikileaks,0.00E+00,45100,2986.619888,55203,7611,29,4128519,8,2290.37931,104.0689655,524.3103448,2.896551724,814.2034734,9.12E-10,2.81303063,1237,0,0,0,0
willmenaker,1,48884,1294.814599,263,1861,88767,16699,1268,9370.252366,1039.211356,687.5544164,25.16009464,1660.330589,9.18E-10,5.643606411,2092,1294,0,0,0
yvessmith,0,14004,2732.176809,1367,294,4,20489,197,10327.2335,651.9898477,994.4010152,30.6142132,1712.405886,1.04E-09,6.030832752,322,0,0,0,0
pairs.csv:
AmberALeeFrost,Trillburne,0,1
ByYourLogic,yvessmith,0,1
CarlBeijer,DannyDeVito,0,1
CenkUygur,Bro_Pair,1,1
ckilpatrick,ebruenig,1,1
CornelWest,LarryWebsite,1,1
cushbomb,adamjohnsonNYC,0,1
davidsirota,ConnorSouthard,0,1
dongoehubaire,cascamike,0,1
DrJillStein,samknight1,0,1
emrata,virgiltexas,1,1
freddiedeboer,BenjaminNorton,0,1
ggreenwald,historyinflicks,0,1
HAGOODMANAUTHOR,crushingbort,1,1
KillerMike,willmenaker,1,1
lhfang,TheBpDShow,0,1
MattBruenig,ninaturner,0,1
mtaibbi,emmettrensin,0,1
mtracey,shailenewoodley,1,1
Pontifex,fart,1,1
PutinRF_Eng,PissPigGranddad,1,1
RaniaKhalek,kthalps,0,1
robdelany,roqchams,1,1
rosariodawson,randygdub,1,1
sam_kriss,DougHenwood,0,1
See_Em_Play,carl_diggler,0,1
SenSanders,JeremyCorbyn,0,1
SenWarren,pattymo,1,1
smoothkobra,karpmj,1,1
SusanSarandon,SenJeffMerkley,0,1
wikileaks,Snowden,1,1
mtaibbi,cushbomb,1,2
sensanders,virgiltexas,1,2
carlbeijer,shailenewoodley,0,2
nickmullen,See_Em_Play,1,2
Bro_Pair,lhfang,0,2
ggreenwald,roqchams,0,2
ebruenig,pattymo,0,2
Snowden,dongoehubaire,1,2
freddiedeboer,fart,1,2
SusanSarandon,LarryWebsite,1,2
randygdub,ByYourLogic,1,2
RaniaKhalek,sam_kriss,1,2
MattBruenig,crushingbort,0,2
willmenaker,PissPigGranddad,1,2
karpmj,AmberALeeFrost,1,2
DrJillStein,ConnorSouthard,0,2
AmberALeeFrost,DrJillStein,0,3
MattBruenig,PissPigGranddad,1,3
sam_kriss,ByYourLogic,1,3
LarryWebsite,cushbomb,1,3
dongoehubaire,fart,1,3
ggreenwald,ebruenig,1,3
See_Em_Play,Bro_Pair,1,3
virgiltexas,carlbeijer,1,3
PissPigGranddad,AmberALeeFrost,1,4
cushbomb,ByYourLogic,1,4
ebruenig,fart,0,4
carlbeijer,Bro_Pair,1,4
ebruenig,PissPigGranddad,0,5
ByYourLogic,Bro_Pair,0,5