Large-Scale Missing Data in a Widely-Published Reddit Corpus
As researchers study complex social behaviors at scale with large datasets, the validity of this computational social science depends on the integrity of the data. That’s why researchers have a duty to check the datasets rather than assume their quality on faith.

Fragments of Plato’s Phaedrus found in Oxyrhynchus. Datasets used by computational social scientists are often just as fragmented, though gaps may not be as obvious.
On July 2, 2015, Jason Baumgartner published a dataset advertised to include “every publicly available Reddit comment,” which was quickly shared on Bittorrent and the Internet Archive. This data quickly became the basis of many academic papers on topics including machine learning, social behavior, politics, breaking news, and hate speech. In a recently published pre-print of an article with Nathan Matias, we have discovered substantial gaps and limitations in this dataset which may contribute to bias in the findings of that research.
Gaffney, D., Matias, J. N. (2018). Caveat Emptor, Computational Social Scientists: Large-Scale Missing Data in a Widely-Published Reddit Corpus. arXiv:1803.05046 [cs.SI]
In our paper, we document the dataset, substantial missing observations in the dataset, and the risks to research validity from those gaps. In total, we find evidence of potentially 36 million comments and 28 million submissions missing between Jan 23, 2015 and June 30th, 2017, scattered throughout the dataset in currently unpredictable ways. We also outline the risk from missing data to common methods in computational social science:
Strong Risks:
- user histories
- network analysis
Moderate Risks:
- comparisons between communities
- participation levels
Lower, but Real Risk:
- machine learning and any other research that avoids making claims about people, communities, or behavior
We believe the total number of papers to be employing this dataset, published or currently underway, to be within the low dozens . Our paper directly cites 15 papers we know to use the data (and we expect that we missed some). These works span over nearly two years of scholarship since the publication of the dataset and represent a broad diversity of research goals.
Identifying Gaps in the Reddit Dataset
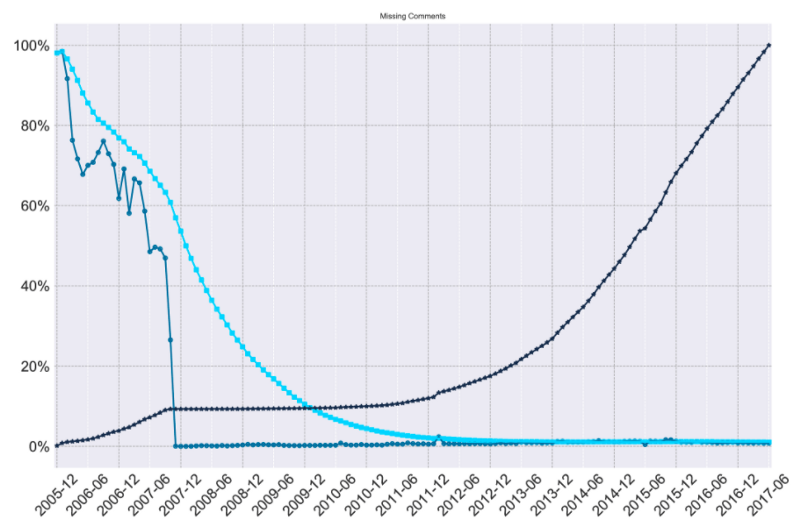
Our analysis of the missing data started by finding easily identifiable impossibilities in the dataset: some comments were in response to posts that did not exist anywhere in the corpus. These “dangling references” were comments that referred to either posts or other comments (since participation in Reddit comment threads is a “tree” of nested comments) that were missing from the dataset. We also chart “unknown unknowns,” which are IDs that “ought” to exist in the Reddit dataset, but are not found in the corpus. Reddit employs a base 26 ID system that monotonically increases for all content on the platform — the first comment was Comment ID #1, the second, #2, and so forth.
Building on this knowledge, we walked through the ID space of submissions and comments. Missing comments are spread unevenly across subreddits as well as time, and this uneven dispersion of error is not (as of yet) explained simply by the size of Reddit at a particular point in time or the size of a subreddit.
{kind=link}
Building on our research, Jason Baumgartner has published a patch for the dataset that fills some, but not all of the gaps–some of the missing data is now beyond anyone’s reach. Additionally, we’re providing a copy of all known missing gaps in the dataset from the start of the dataset to June 2017 (the latest we checked).
Improving Research Through Open Discussion of Missing Data Problems
We do not intend for this to be a “gotcha” paper targeting existing literature. We have sent a copy of our paper to all of the research teams we cite, and some have already updated their findings based on what we learned (we’ll post links below as more become available). Jason has worked closely with us to understand and resolve as many of the issues as possible.
Our finding is just one instantiation of a persistent problem in computational social science — research is limited by the datasets we employ and any biases, known or unknown, present within those datasets.
Jason Baumgartner’s dataset has been a phenomenal resource for computational social science, and we expect that it will continue to yield important discoveries. The onus is on researchers to recognize the limitations of the data, properly account for them, and document how these issues influence our findings.
Please share this article with anyone you know who wants to use this dataset. We also encourage reviewers to ask that authors account for any missing data in their papers.
If you are a researcher who wants to use the Reddit dataset, please do not just cite our paper and ignore the issues we raise. We strongly encourage any researcher to take the following steps:
Patch the dataset with Jason’s update, knowing that it only fills some gaps
Report the amount of missing data affecting your paper, by applying methods similar to ours on the part of the dataset you investigate
Find out how sensitive your findings are to missing data by simulating data to fill the gaps, and then use that simulated data to calculate upper and lower bounds on your findings
Accounting for missing data takes work and will increase the time it takes you to complete your research. Since flawed findings are hard to correct once they reach the public, we encourage you to invest that time when doing research with this dataset.
We’re grateful for all of the authors who have revisited their past research in light of these findings. For this reason, we plan to update this post and the appendix of our paper with information on any re-analysis that is conducted by researchers who have historically used this data. We hope this will help everyone strengthen the quality of our work together.